En NSI, nous allons uniquement utiliser le système GNU\/Linux. C'est pourquoi nous allons détailler un peu plus le fonctionnement de ce système.
Le système installé au lycée est Ubuntu, un système commercial basé sur la distribution Debian. Dans la suite de ce cours ce que nous disons s'applique à tout les systèmes GNU\/Linux, nous ne parlerons donc pas spécifiquement de Ubuntu ni Debian.
Ce cours ne détaille pas les différentes commandes utilisées, mais quelques principes fondamentaux de ce système. Les commandes que l'on apprend à utiliser avec Terminus ou Gameshell sont elles détaillées dans le cours suivant.
Le système GNU\/Linux⚓︎
Pour l'historique du système, regardez le cours correspondant: https://nsi.codeberg.page/premiere/sys/hist/#linux
GNU\/Linux est un système d'exploitation dit libre (https://nsi.codeberg.page/premiere/sys/free-software/), contrairement à Windows ou MacOs. De plus, contrairement à ces deux systèmes très grand publics, GNU\/Linux fait la grande part à l'utilisation via la ligne de commande ou CLI.
Nous allons ici étudier GNU\/Linux à travers deux éléments principaux:
- Son système de fichiers
- Son interface en ligne de commande
Système de fichiers⚓︎
Le stockage des fichiers dans la mémoire de masse se fait avec deux types d'objets:
- Les fichiers: Qui stockent des données, comme les fichiers textes, exécutables, de configuration ...
- Les répertoires (ou dossier): Qui stockent des fichiers et des répertoires.
Linux et les fichiers
On peut parfois lire: dans les systèmes GNU\/Linux tout est fichier. Cette affirmation est due à la manière dont ces systèmes organisent les données sur le disque.
En effet, dans ces systèmes, l'accés aux périphériques, aux informations temporaires, ... se fait via des fichiers. Les répertoires eux-mêmes sont des fichiers, qui stockent une liste de liens vers d'autres fichiers (pour simplifier).
Ce choix de conception permet une plus grande facilité de gestion, en effet il n'y a qu'un seul type d'objet à manipuler. Ainsi, il est aussi simple d'ouvrir un fichier texte, que d'envoyer des données à l'écran ou bien via une connexion internet.
Le système de fichier est dit hiérarchique car les données sont organisées dans des répertoires, eux mêmes stockées dans un répertoire dit répertoire parent. L'organisation des fichiers personnels de l'utilisateur·ici est quelconque, sauf quelques fichiers de configuration. Celle des fichiers du système est elle dictée par un standard, le FHS.
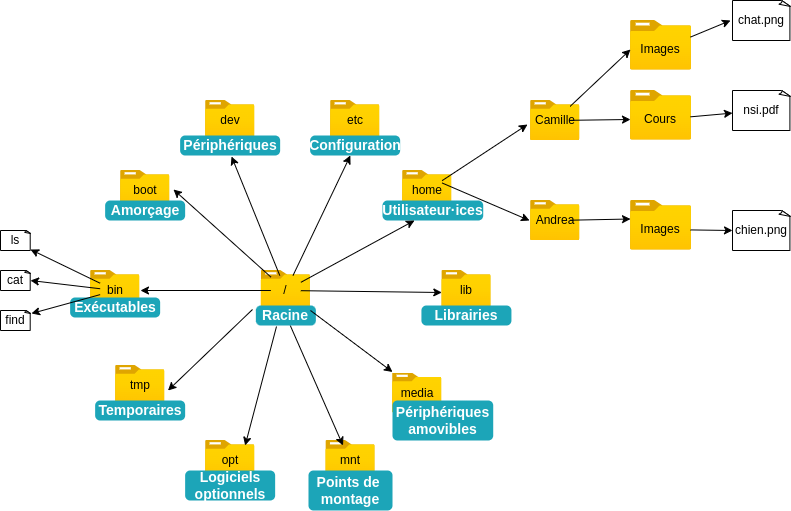
La racine
Dans ce système de fichier on peut distinguer un répertoire principal: la racine.
Ce répertoire est aussi nommé / car il correspond au séparateur de fichiers, sans aucun répertoire parent ni enfant.
Les répertoires personnels
Un autre répertoire particulier, spécifique à chaque utilisateur·ice, est le répertoire personnel.
Chaque utilisateur·ice dispose d'un répertoire personnel, situé dans le répertoire /home/ et nommé comme l'utilisateur.
Par exemple, le répertoire personnel de l'utilisateur·ice Camille sera désigné par le chemin /home/Camille
Les fichiers cachés
Sous GNU\/Linux, la notion de fichier caché est bien plus simple que sous Windows.
On définit comme caché, tout fichier dont le nom commence par un ..
Cette convention indique que les programmes de visualisations du système de fichiers ne doivent pas afficher ces fichiers par défaut.
Contrairement à Windows, il n'y a donc aucune métadonnée indiquant si le fichier est visible ou non.
Ainsi, le fichier .fichier est caché alors que celui se nommant fichier ne l'est pas.
Les extensions
Contrairement à Windows, les extensions de fichier ne sont pas si importantes sous GNU\/Linux. Certaines distributions comme Ubuntu les utilise, mais la plupart du temps ce sont des informations internes au fichier qui décide de son type.
Ainsi, il n'est pas rare qu'un fichier se nomme juste Présentation et non Présentation.odp sous GNU\/Linux.
Désigner des fichiers⚓︎
On peut désigner tout fichier d'un système depuis la racine.
Par exemple, le fichier de configuration des utilisateur·ices se trouvent toujours dans : /etc/passwd.
Les chemins absolus
Un chemin absolu est un chemin qui commence toujours à la racine, donc par un /.
Il est suivi par une suite de noms de répertoires, séparés par des /.
Lorsqu'on désigne ainsi un fichier (ou un dossier) depuis la racine, on parle de chemin absolu.
Le chemin désigne absolument le fichier, sans ambiguïtés possible.
On peut parler, au contraire des chemins absolus, des chemins relatifs. Les chemins relatifs eux, ne désignent pas le même fichier selon dans quel répertoire on se trouve. On dit qu'ils sont relatifs au répertoire courant.
Le répertoire courant
Lorsqu'on se déplace dans un système de fichiers, le répertoire où on est situé à un instant donné se nomme le répertoire courant.
Il est parfois désigné par le signe ..
Ainsi, le fichier "fichier.txt" situé dans le répertoire courant peut être désigné par le chemin relatif ./fichier.txt.
À partir de cette notion de répertoire courant, on définit les chemins relatifs, comme des chemins partant du répertoire courant.
Les chemins relatifs
Un chemin d'accès relatif tient compte du répertoire courant dans la formation du chemin. Il donne donc la liste des répertoires à traverser en partant du répertoire courant pour atteindre un fichier ou répertoire donné.
De même que dans un chemin absolu, les répertoires sont séparés par des /.
Chemins d'accès
Pour accéder au répertoire "Cours" de l'utilisateur·ice "Camille", on pourra utiliser le chemin relatif: Cours ou bien le chemin absolu /home/Camille/Cours.
Chaque répertoire contient deux répertoires virtuels ( qui ne sont pas physiquement présents sur le disque ):
.qui correspond au répertoire courant...qui correspond à son répertoire parent.
Répertoire parent
Toujours avec notre utilisateur·ice Camille et son dossier Cours, on peut supposer que ce dossier contient un autre dossier "NSI".
Alors on peut accéder au dossier "Cours" depuis NSI avec le chemin ../ et au répertoire personnel de Camille avec : ../../, soit le parent du parent.
Attention, le répertoire parent n'est pas le répertoire précédent mais le répertoire situé au dessus dans la hiérarchie du système de fichier.
Décomposer un chemin
Le chemin d'accès à un fichier est toujours composé de la même façon:
- On commence par nommer le répertoire de départ (rien si on part de la racine).
- Ensuite on ajoute le séparateur de fichier
/ - Puis on ajoute les répertoires intermédiaires, tous séparés par des
/ - Enfin, on nomme le fichier.
Par exemple, le chemin vers le fichier /home/Camille/Cours/nsi.pdf se lit comme: Le fichier "nsi.pdf", situé dans le répertoire "Cours", situé dans le répertoire personnel de l'utilisateur "Camille".
Ou bien comme: En partant de la racine, on va dans le répertoire personnel de Angie, puis dans le répertoire "Cours" et on a le fichier "nsi.pdf".
Interface en ligne de commande⚓︎
On a l'habitude aujourd'hui de lancer des processus ou applications via les interfaces graphiques. Le plus souvent on clique sur un icône pour lancer un logiciel, on fait un glisser-déposer pour changer un fichier de place et ainsi de suite.
Il existe cependant une autre interface, nommée la ligne de commande (ou CLI), accessible facilement sur les systèmes GNU\/Linux. Cette interface est purement textuelle et se manipule au travers de l'application Terminal ou Console, selon les systèmes.

L'interface en ligne de commande pour un·e utilisateur·ice normal·e, comprend le nom de la personne, le nom de la machine, le répertoire courant et finit souvent par un $. Lorsque ce prompt est affiché, cela signale que l'invite de commande, aussi appelé Shell, est prêt à recevoir des commandes.
Le prompt et le Shell
Le prompt correspond à tout ce qui est affiché avant la commande que vous tapez.
Dans notre exemple il s'agit de personne@nom_machine:repertoire$.
Le Shell lui est l'environnement global qui affiche le prompt et permet de taper les commandes.
Si l'utilisateur·ice en question est lae super-utilisateur·ice, le prompt sera légèrement différent et sera plutôt comme suivant (notez le # à la fin de la ligne au lieu du $).

Cet·te utilisateur·ice a tout les droits sur la machine. L'utiliser est donc très dangereux car iel peut tout modifier et supprimer potentiellement.
Un prompt
Si l'utilisateur·ice Camille a un compte sur une machine nommée "PC-NSI" et lance un Shell dans le répertoire /etc, le prompt affiché sera:
Camille@PC-NSI:/etc$
On verra souvent si Camille est dans son répertoire personnel le prompt suivant, avec un ~ en lieu et place de /home/Camille:
Camille@PC-NSI:~$
Pourquoi utiliser l'interface en ligne de commande ?⚓︎
Aujourd'hui, l'interface graphique est la plus utilisée sur les ordinateurs personnels. Elle est le plus souvent basée sur les travaux du parc Xerox, qui ont implantés les premiers travaux sur les interfaces graphiques.
Cependant, l'interface en ligne de commande est souvent utilisée de manière programmative, de par sa simplicité. Elle est aussi beaucoup utilisée lors de la connexion à des machines sans écran, comme les serveurs par exemple.
De plus, l'interface en ligne de commande est bien plus accessible que l'interface graphique car:
- elle se base uniquement sur le texte et peut donc être appréhendée par les interfaces de lecture.
- elle ne dépend pas des systèmes
- elle est indépendante du matériel car purement textuelle
Ainsi, la plupart des tutoriels de configuration ou de modification des systèmes GNU\/Linux se font via la ligne de commande, pour sa simplicité et son universalité.